Literature Review: Large Language Models are Autonomous Cyber Defenders
Summary
This paper investigates the capabilities of Large Language Models (LLMs) as autonomous cyber defense (ACD) agents, particularly in multi-agent environments, and compares their performance and reasoning to traditional Reinforcement Learning (RL) agents. The authors introduce a novel framework for integrating LLMs into the CybORG CAGE 4 simulation environment, enabling mixed teams of LLM and RL agents to defend networks against adversarial threats. The study also proposes a new communication protocol for agent collaboration and evaluates both agent types across various adversarial scenarios. Key findings highlight LLMs’ strengths in explainability and adaptability, while also identifying their limitations in speed, reward optimization, and susceptibility to prompt engineering and hallucination.
Key Insights
1. LLMs as Autonomous Cyber Defenders
- LLMs can serve as ACD agents, providing explainable, human-interpretable decisions in simulated cyber defense scenarios.
- Unlike RL agents, LLMs do not require environment-specific training and can generalize knowledge from diverse threat models and networks, leveraging their pre-training.
2. Multi-Agent Integration and Communication
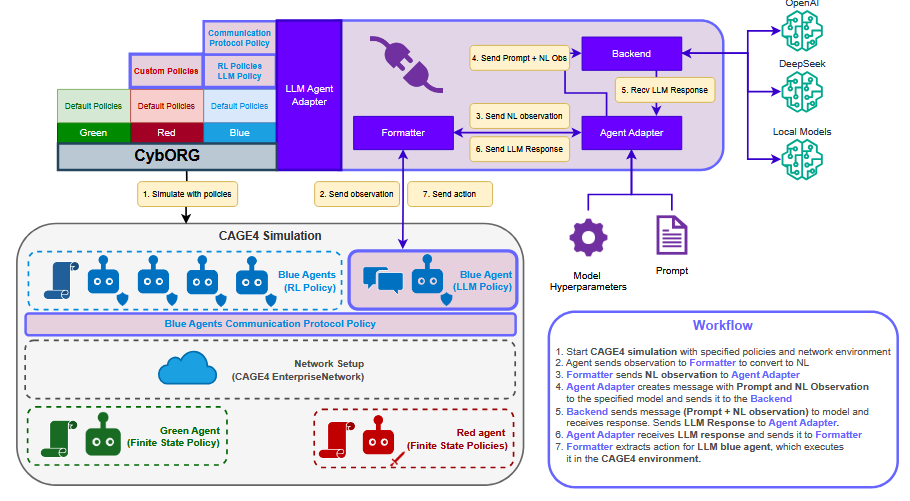
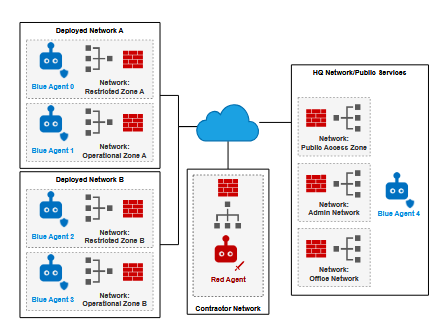
- The paper presents the first integration of LLMs and RL agents in a multi-agent cyber defense setting using CybORG CAGE 4.
- A novel 8-bit communication protocol allows agents to share threat intelligence, network security levels, and their operational status efficiently, enhancing team coordination.
3. Natural Language Observation and Action Formatting
- Observations from the simulation are translated into natural language prompts for LLMs, enabling them to process and reason about network states similarly to human experts.
- LLM responses are parsed for structured actions and justifications, with fallback mechanisms for invalid outputs.
4. Prompt Engineering and Model Selection
- The study demonstrates that prompt design significantly affects LLM performance. Role-based and few-shot prompting yields better results than instructional prompting alone.
- Lightweight models (e.g., GPT-4o-mini) offer a tradeoff between inference speed and reward, but still lag behind RL agents in raw performance.
5. Experimental Evaluation
- RL agents (KEEP GNN PPO) consistently outperform LLMs in terms of the CAGE 4 reward function, especially under diverse adversarial strategies.
- LLM agents excel in explainability and adaptability, often providing nuanced reasoning for their actions and showing flexibility in unfamiliar scenarios.
- LLMs are notably slower (up to 150x) than RL agents due to inference overhead, making real-time deployment challenging.
6. Action Selection and Reasoning Analysis
- Clustering and embedding analysis of LLM-generated justifications reveal coherent, security-driven strategies (e.g., proactive decoy deployment, targeted analysis, and response to peer alerts).
- LLMs favor deception and analysis actions, while RL agents tend toward passive monitoring and conservative interventions to minimize penalties.
- LLMs occasionally hallucinate or misinterpret communication vectors, highlighting the need for more robust prompt engineering and action definition.
7. Limitations and Future Directions
- The CAGE 4 environment is tailored for RL, potentially biasing reward functions against LLMs.
- LLMs’ lack of explicit training on the reward structure and their reliance on prompt clarity can hinder optimal performance.
- Future work should explore hybrid strategies, improved prompt engineering, and model fine-tuning for cyber defense contexts.
Example
Scenario:
A blue (defender) agent receives an observation indicating suspicious activity on a host and a peer agent’s alert of potential compromise.
LLM Agent Response:
{“action”: “Analyse host-3”, “reason”: “Suspicious connections detected and peer agent reported possible compromise; further analysis is required before taking disruptive action.”}
RL Agent Response:
- Monitors or sleeps, only escalating to analysis if repeated suspicious activity is detected, to avoid unnecessary penalties.
Ratings
| Category | Score | Justification |
|---|---|---|
| Novelty | 4.5 | First to systematically evaluate LLMs as ACD agents in a multi-agent, mixed-team setting with a new communication protocol. Integration into CybORG and the focus on explainability are notable, though the use of LLMs for cyber defense is an emerging trend. |
| Technical Contribution | 4.5 | Introduces a robust framework for LLM integration with RL agents, a novel agent communication protocol, and detailed evaluation methodology. |
| Readability | 4 | The paper is well-structured, with clear explanations, tables, and figures. Key concepts are accessible to non-experts, though some sections assume familiarity with RL and cyber defense simulation environments. Figures and tables enhance understanding. |
Enjoy Reading This Article?
Here are some more articles you might like to read next: