Literature Review: Dissecting Recall of Factual Associations in Auto-Regressive Language Models
This paper shifts the focus from where factual knowledge is stored in transformer-based LMs to how it is retrieved during inference. The authors propose an information flow perspective, identifying a three-step mechanism in factual recall for subject–relation queries: (1) subject enrichment via early MLP sublayers, (2) relation propagation to the prediction position, and (3) attribute extraction by upper-layer MHSA heads. They use fine-grained “attention knockout” interventions to localize when and where information propagates, revealing that critical flows from relation tokens occur before flows from subject tokens. The work emphasizes that information retrieval is internally distributed and sequential, rather than localized in a single neuron or layer.
Key Insights
- Subject enrichment as a distributed process Early-to-mid MLP sublayers build up semantically related attributes in the last-subject token representation. This enrichment is broad, not tied to a single fact, and can reach nearly 50% “attribute rate” (percentage of high-probability tokens related to the subject).
-
MHSA-driven attribute extraction Upper-layer attention heads frequently encode subject–attribute mappings directly in their parameters, acting as “knowledge hubs”.
-
Importance of early MLPs for downstream extraction Ablating early MLP contributions sharply reduces attribute rate in subject representations, which in turn lowers the extraction success rate.
- Extraction is non-trivial The target attribute often has a low rank in the enriched subject representation before being elevated to rank 1 by MHSA updates, indicating active selection rather than passive copying.
Example
For the query “Beats Music is owned by ___”:
- Early layers enrich the last-subject token “Music” with a wide set of related terms (e.g., “Apple”, “iPod”, “iOS”, “speakers”).
- Mid layers propagate relation information (“is owned by”) to the final position.
- Upper layers perform extraction: specific MHSA heads map from the “Beats Music” representation to the attribute “Apple”, which may be encoded directly in the head’s parameter space.
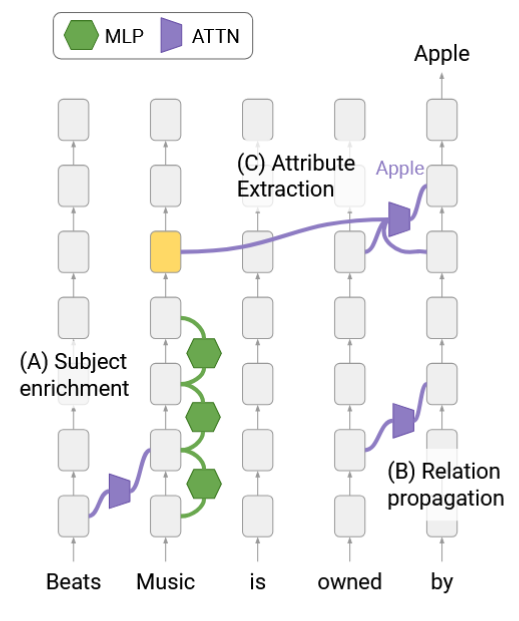
Figure: Identified three-step process: MLP-driven subject enrichment, relation propagation, and MHSA-based attribute extraction.
Ratings
Novelty: 4/5 The intervention-based tracing of flow rather than static location is a meaningful shift, though still within established mechanistic interpretability paradigms.
Clarity: 4/5 The paper’s structure is logical, with clear diagrams and well-motivated methodology, though some metric definitions (i.e. attribute rate) require careful reading.
Personal Comments
This paper’s departure from the neuron-centric “fact storage” framing that we have come to have aligns with a growing interest in mechanistic interpretability: knowledge recall is inherently a process, not a fixed match. The results show that attention heads can embody dense subject–attribute mappings, making them potential triggers for targeted editing or robustness interventions.
Concerns remain about scalability as attention knockout is computationally heavy, and the method assumes clean subject–relation–attribute structures that may not generalize to noisier, multi-entity contexts. Additionally, while the identification of “knowledge hubs” is interesting, the functional role of these hubs under distribution shifts is unexplored.
If extending this work, I would:
- Probe robustness under adversarial paraphrasing to see if the same heads are responsible for extraction.
- Apply similar flow-tracing to non-factual, compositional reasoning tasks, testing whether a similar enrichment–propagation–extraction pipeline exists.
Enjoy Reading This Article?
Here are some more articles you might like to read next: