Literature Review: Context Rot — How Increasing Input Tokens Impacts LLM Performance
This technical report analyzes how model performance changes as input length grows across a suite of tasks and 18 models. The authors isolate length from task difficulty by fixing the “needle–question” pair while increasing irrelevant context, then expand to distractor sensitivity, long-chat reasoning with LongMemEval, and a repeat-after-me stress test where output length scales with input.
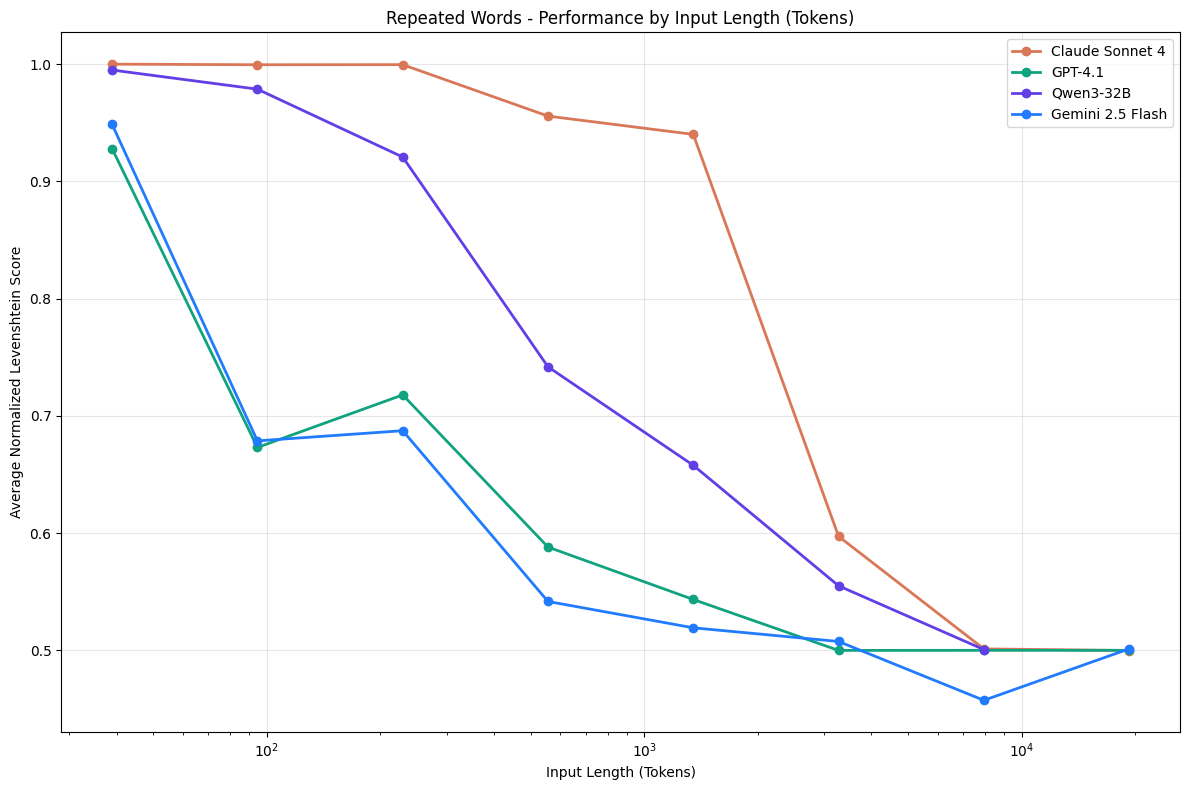
Figure: Schematic summary of context rot. As context grows, accuracy falls faster when question–evidence similarity is low, when distractors are semantically confusable, and when haystack structure is shuffled. Focused prompts outperform full long prompts even for models with chain-of-thought.
Key Insights
-
Length is not neutral
Performance degrades with increasing input length even when the underlying task is trivial to the model at short lengths. Holding the needle–question pair fixed while padding with irrelevant text cleanly shows the effect. -
Semantic alignment matters more as you go long
When question and evidence share high semantic similarity, models tolerate more padding. With low-similarity pairs, accuracy decays earlier and faster. This suggests that subtle signals lose to locally coherent but irrelevant spans as length grows. -
Distractors scale the pain, and not all distractors are equal
Semantically close distractors degrade performance more than generic irrelevant text, and specific distractors consistently cause larger drops than others. Different model families show distinct failure profiles, which suggests family-specific inductive biases in retrieval under ambiguity. -
Focused vs full prompts in long-chat QA
On LongMemEval, compressing to the minimal relevant spans (hundreds of tokens) beats feeding the full long chat (hundreds of thousands of tokens), even with reasoning enabled. Thinking budgets raise both curves yet do not close the focused–full gap. -
Output-length coupling reveals stability limits
A simple repeat-after-me program should be deterministic, yet models introduce random strings, refuse, or misplace the one unique token as sequence length grows. Position accuracy is best when the unique token is early, and some models emit refusals or garbage at mid–high lengths.
Ratings
Novelty: 2/5 A careful, multi-angle empirical study that triangulates known long-context pitfalls with new controls and failure taxonomies.
Clarity: 4/5 Clear task definitions, controlled manipulations, and interpretable plots. Mechanistic claims are explicitly out of scope, which keeps the narrative honest.
Personal Comments
This is the study I wanted to see for a while, since anecdotes about long prompts going sideways have been common. The controlled sweeps confirm that length interacts with semantics and structure, not just raw capacity. The distractor analysis is especially useful since real deployments rarely have clean haystacks. I appreciate that “thinking” helps but does not erase focused–full gaps, which aligns with experience that chain-of-thought often shifts failure classes rather than fixing them.
Enjoy Reading This Article?
Here are some more articles you might like to read next: