Literature Review: Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models
This paper introduces the concept of the LLM safety landscape, highlighting a universal phenomenon called the safety basin: locally perturbing model weights preserves alignment, but stepping outside this region causes a sharp drop in safety. To quantify this, the authors propose VISAGE (Volumetric Index for Safety Alignment Guided by Explanation), a new safety metric designed to measure the stability of alignment under perturbations. Using this framework, they analyze how finetuning drags models out of the safety basin, the role of system prompts, and the sensitivity of jailbreak attacks to weight perturbations.
Key Insights
-
Safety Basin Discovery All tested open-source LLMs (LLaMA2, LLaMA3, Vicuna, Mistral) show step-function-like safety behavior: locally robust to perturbation, but fragile once outside the basin. Harmful finetuning pulls models out of the basin, breaking safety rapidly.
-
VISAGE Metric VISAGE measures how far safety extends around a model’s parameter point. Unlike raw attack success rates (ASR), it reflects robustness of alignment under perturbation and predicts vulnerability to harmful finetuning before it happens.
-
System Prompt as Anchor Prompts play a critical role: removing or altering them reduces safety, while optimized prompts can transfer robustness across perturbed variants.
-
Jailbreak Sensitivity Jailbreak prompts are surprisingly fragile to weight perturbations, slight randomization can reduce attack success, though attackers can adapt by targeting perturbed ensembles.
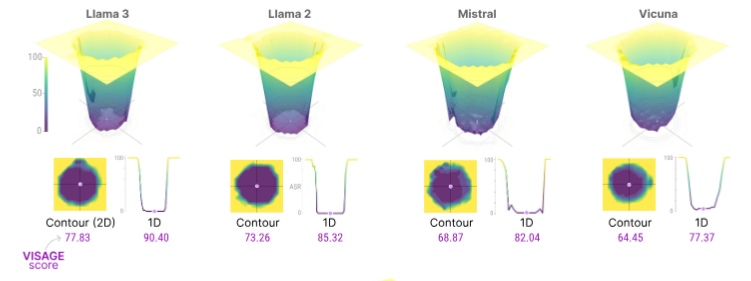
Figure: Illustration of the "safety basin". Local perturbations maintain alignment, but moving outside the basin causes a sudden collapse in refusal behavior.
Ratings
Novelty: 4/5
The safety basin phenomenon and VISAGE metric offer fresh perspectives, though the reliance on existing evaluation proxies (keyword detection, AdvBench) limits the depth.
Clarity: 3/5
The paper is readable, but the heavy reliance on landscape visualizations without richer qualitative examples or capability-safety tradeoff analyses reduces accessibility.
Personal Comments
The safety basin framing is conceptually powerful, but I remain concerned about the tradeoff with capability. The paper’s Section 7 acknowledges this but does not explore it deeply: safety can be preserved locally, but is capability sacrificed if we try to “stay inside the basin”? Without testing whether models remain equally useful while safe, conclusions feel incomplete. Every safety study should pair alignment results with capability outcomes, otherwise we risk presenting false security by focusing only on refusal.
Another weakness is the measurement method. Using keyword pattern matching for refusal (e.g., checking for “I cannot…” phrases) is brittle. A model could explain bomb-making in neutral terms without triggering keywords, or conversely, refuse benign queries with “dangerous” terminology. Qualitative case studies are tucked into the appendix, but the main narrative would benefit from more attention to this issue. Safety is nuanced; metrics alone cannot capture it.
Still, the visualization approach is novel and echoes earlier work on loss landscapes in deep nets. It reminds me of how flat minima were connected to generalization. Here, a “flat safety basin” suggests robustness, while sharp corners imply brittleness. Historically, such geometric insights have often guided training strategies, so I can see this inspiring new regularization objectives aimed at widening the basin during alignment.
Enjoy Reading This Article?
Here are some more articles you might like to read next: