Literature Review: Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
This paper introduces Stochastic Error Ascent (SEA), a framework designed to uncover factual deficiencies in large language models (LLMs) by formulating error discovery as a stochastic optimization problem under query budget constraints. Instead of exhaustively probing massive knowledge bases, SEA iteratively identifies error-prone regions by leveraging semantic similarity to prior failures, constructing a relation DAG to trace error propagation, and pruning redundant nodes. Empirically, SEA claims to outperform Automated Capability Discovery (ACD) and AutoBencher in error detection efficiency and cost-effectiveness. It further reports a 100% human evaluation pass rate for generated questions.
Key Insights
-
Optimization Framing of Error Discovery
SEA treats evaluation as a stochastic optimization problem: maximize discovered errors under a strict budget. This reframing allows hierarchical retrieval (document → paragraph) and the construction of relation DAGs to map systematic weaknesses, though the formalization is difficult to parse in practice. -
Systematic Error Mapping Across Models
The method highlights error clusters in domains like chronological reasoning, arts, and sciences, revealing correlated weaknesses across families (e.g., GPT vs. DeepSeek). This suggests that benchmark-driven training may reinforce blind spots rather than close them. -
Cost-Efficiency as a Central Metric
By reporting “cost per error” alongside error discovery rates, the work foregrounds the economics of evaluation. For closed-weight commercial models, budget-aware testing is an important framing, though the practical assumptions about budget choice remain underspecified.
Example
Consider the example of the incorrect attribution of an artwork: SEA identified that a model claimed Marcel Janco painted Portrait of Tristan Tzara in 1923 with oil on canvas. In reality, Robert Delaunay created it using oil on cardboard. This illustrates how SEA surfaces subtle but consequential factual errors that static QA benchmarks would rarely expose.
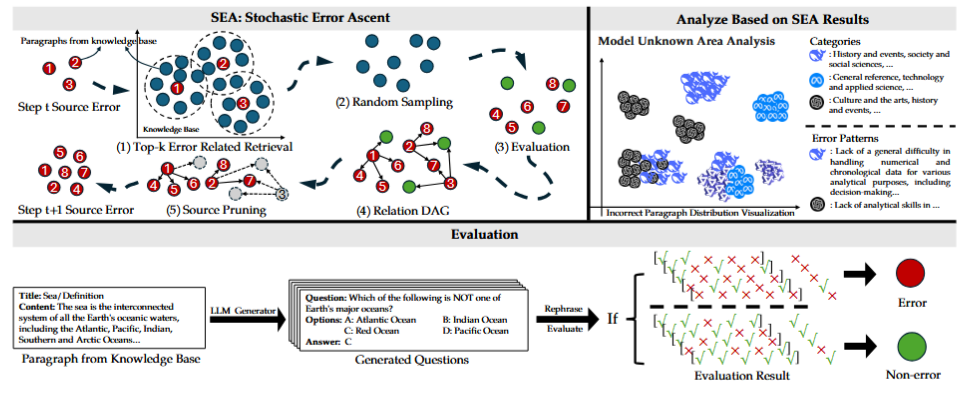
Figure: SEA workflow. The algorithm iteratively retrieves semantically related errors, updates a relation DAG to trace propagation, and prunes low-quality nodes, enabling efficient error discovery under budget constraints.
Ratings
Novelty: 3.5/5
Reframing benchmarking as stochastic optimization is a meaningful contribution, but many underlying components (retrieval, similarity search, pruning) are incremental adaptations of existing techniques. The dynamic benchmarking idea is valuable but not entirely new.
Clarity: 2.5/5
The presentation is dense, with excessive formalism and inconsistent notation. The central algorithm is obscured by symbol-heavy equations and a cluttered diagram. Human evaluation methodology is thinly justified (five college-level students, no qualitative analysis).
Personal Comments
The paper’s core motivation is sound, LLM benchmarks should be dynamic and adaptive, not static artifacts that can be gamed. Framing evaluation as a stochastic optimization process is conceptually appealing, but the exposition makes it unnecessarily difficult to follow. The formalism feels heavier than required, especially given the relatively simple retrieval and pruning mechanisms.
The evaluation also raises questions. Reporting a “100% human pass rate” with just five annotators is insufficient for claims of robustness. There is also a missed opportunity for qualitative assessment of generated questions or discovered errors, what kinds of errors are most meaningful, and how do they impact downstream applications?
Future iterations should focus less on optimization gloss and more on interpretability of discovered errors, integration with real-world safety testing, and richer human analysis. An important open question is whether these adaptive benchmarks can themselves avoid becoming overfitted as training targets.
Enjoy Reading This Article?
Here are some more articles you might like to read next: