Literature Review: Agent A/B — Automated and Scalable Web A/B Testing with Interactive LLM Agents
This paper presents Agent A/B, an end-to-end system that uses LLM-driven agents with structured personas to simulate web-based A/B testing at scale. Motivated by bottlenecks in traditional A/B testing—scarcity of traffic, slow feedback, and high costs—the system aims to provide faster, lower-risk insights for interface evaluation before committing live user traffic. A case study on Amazon.com shows that LLM-agent simulations produce behaviorally rich signals that directionally align with human A/B experiments.
Key Insights
-
End-to-End Framework
Agent A/B introduces a pipeline that covers agent specification, testing setup, live agent–web interaction, behavioral monitoring, and automated post-test analysis. It integrates environment parsing, persona-driven LLM agents, and Selenium execution for live web pages. -
Persona-Driven Simulations
The system generates diverse agent personas (up to 100,000) that capture demographics, behavioral traits, and shopping intentions. These personas guide the decision-making and interaction patterns of LLM agents, enabling subgroup analyses (e.g., by age or gender).
3) Scalable Interaction with Real Websites
Unlike prior benchmarks that use sandboxed environments, Agent A/B runs directly on live web platforms. Using structured JSON parsing of DOM elements and an iterative action loop, the agents perform realistic tasks such as searching, filtering, and purchasing.
4) Case Study Validation
In a large-scale Amazon test, 1,000 agents simulated shopping sessions under two filter-panel designs. Results showed more purchases under the reduced-filter condition (414 vs. 403), aligning with directional outcomes in a parallel human A/B test with 2M participants.
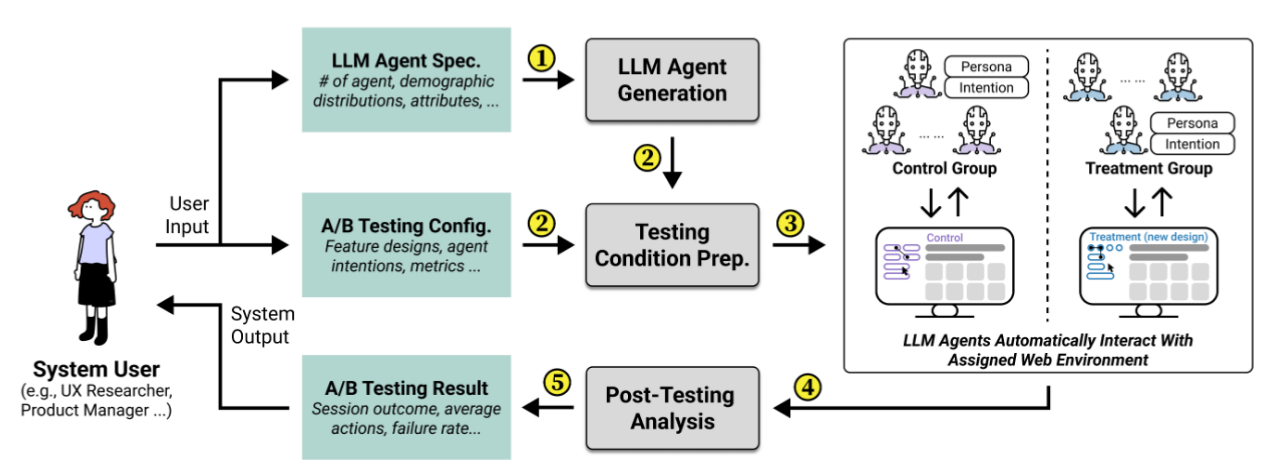
Figure: Agent A/B pipeline. Personas are instantiated into LLM agents, which interact with live webpages through Selenium to simulate A/B experiments.
Example
In the Amazon case study, LLM agents role-played shopping personas and completed sessions capped at 20 actions. Under the reduced-filter condition, agents made slightly more purchases than under the full-filter baseline. Subgroup analyses suggested that older and male personas benefitted most, while younger personas spent less under the new design. These findings paralleled human A/B test results, supporting the claim that agent simulations can anticipate real user behavior.
Ratings
Novelty: 3/5
The integration of LLM agents into A/B testing pipelines is new in practice, but primarily an engineering contribution rather than a conceptual breakthrough.
Clarity: 3/5
The paper is well-structured and readable, though technical details of scalability and persona generation are under-specified.
Personal Perspective
This work is positioned as a practical HCI system rather than a theoretical advance. The appeal lies in its promise to shorten design cycles, provide lightweight pre-deployment validation, and explore underrepresented user groups without risk. My concerns are with fidelity and feasibility. Personas generated by LLM prompts may not capture the variability of real human populations. Not only that, claims of scalability to 100k agents are not backed by computational analysis, given the reliance on Selenium instances. And most important of all: behavioral alignment is modest at best: agents are efficient and deterministic, while humans are exploratory and unpredictable.
Agent A/B seems to be a cool proof-of-concept tool, but not yet a rigorous method for scientific evaluation of user behavior. Future work should benchmark against cognitive models, explore multimodal agents, and provide stronger guarantees on scalability and validity.
Enjoy Reading This Article?
Here are some more articles you might like to read next: