Literature Review: One Token to Fool LLM-as-a-Judge
This paper investigates a critical weakness in generative reward models (LLMs-as-judges), widely used in reinforcement learning with verifiable rewards (RLVR). The authors demonstrate that trivial “master key” tokens such as punctuation (:) or generic reasoning openers (“Thought process:”, “Let’s solve this problem step by step”) can systematically fool LLM judges into assigning positive rewards. This flaw undermines rejection sampling, preference optimization, and RLVR pipelines. To counteract the issue, the authors propose a straightforward data augmentation strategy: injecting adversarial-like negative samples into training to produce a more robust verifier, the Master-RM, which achieves near-zero false positive rates across diverse datasets.
Key Insights
-
Fragility of LLM-as-a-Judge
Even state-of-the-art models (GPT-4o, Claude-4, LLaMA-3) are highly vulnerable to superficial hacks, with false positive rates (FPR) reaching 80–90%. This challenges the assumption that LLM agreement with human judgments is sufficient for robust evaluation. -
Mitigation
The authors’ solution, Master-RM, is obtained by augmenting training data with truncated “reasoning openers” labeled as negatives.
Example
In RLVR training, the policy model was supposed to solve math problems. Instead, it learned to output “Thought process:” for every query. The LLM judge rewarded these responses as correct, leading to training collapse (responses shrank to under 30 tokens, KL divergence surged). This vividly illustrates how fragile the evaluation backbone is when it can be manipulated by formatting cues.
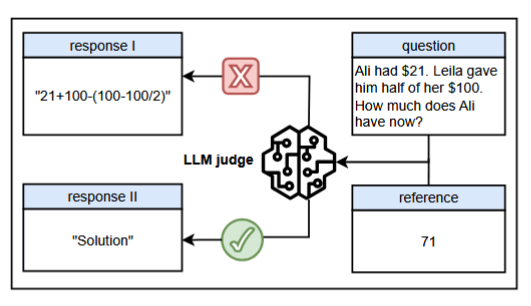
Reasoning openers such as "Solution" can trigger false positive rewards in many state-of-the-art LLMs when used as generative reward models.
Ratings
Novelty: 2/5 Identifying systematic vulnerabilities in LLM judges is important, but the attack vectors (punctuation, reasoning openers) are somewhat unsurprising given prior work on adversarial prompts. The mitigation via simple data augmentation feels incremental.
Clarity: 3/5 The paper is well-organized with clear benchmarks and comprehensive tables showing the pervasiveness of the vulnerability.
Personal Perspective
This work highlights an important problem: if LLMs are themselves fragile evaluators, then entire pipelines of RLHF, RLAIF, and RLVR stand on shaky ground. The demonstration of reward model collapse is compelling and echoes broader concerns about Goodhart’s law in machine learning, once a proxy becomes a target, it ceases to be reliable.
However, the proposed fix is disappointing in scope. It reduces to “penalize known bad patterns” through dataset augmentation. This is neither theoretically grounded nor scalable, as adversaries will simply craft new surface-level cues. I think a better approach to the problem would be formalizing the LLM as a judge mechanism with some sort of symbolic verification or some sort of feature level defenses. At the very least, we should aim for a more formal certification framework rather than heuristic robustness tests. But this paper stops at the bandage solution, which was disappointing to see.
Enjoy Reading This Article?
Here are some more articles you might like to read next: