Literature Review: Knowledge Awareness and Hallucinations in Language Models
This paper investigates the role of sparse autoencoders (SAEs) in uncovering internal mechanisms that regulate whether LLMs hallucinate or refuse to answer. Unlike prior SAE interpretability work focused on factual recall or safety refusal, this study flips the lens toward hallucinations, analyzing how models internally represent “known” versus “unknown” entities. The authors argue that models encode a form of knowledge awareness: latent directions that determine if the system recalls facts about an entity, which in turn influences refusal or hallucination behaviors.
Key Insights
-
Entity Recognition Directions SAEs reveal distinct latent directions corresponding to whether an entity is recognized by the model. These directions generalize across domains (movies, players, cities, songs) and are most interpretable in middle layers, consistent with prior SAE findings.
-
Mechanistic Circuit Effects The entity recognition directions regulate downstream attention heads responsible for factual attribute extraction. Unknown entity latents reduce attention to entity tokens, disrupting factual recall, while known entity latents amplify attention and encourage confident but sometimes false answers.
-
Uncertainty Directions Beyond refusal, the authors identify SAE latents predictive of incorrect answers, which align with textual uncertainty markers (e.g., “unknown,” “not disclosed”). These “uncertainty directions” suggest LLMs internally represent shades of epistemic uncertainty that do not surface reliably in outputs.
Example
When asked, “When was Wilson Brown born?” (a non-existent player), Gemma 2B typically refuses. But when the known entity latent is up-weighted, the model hallucinates a detailed biography. Conversely, steering with the unknown entity latent makes the model refuse even on familiar names like LeBron James. This demonstrates the causal control of hallucination versus refusal behaviors.
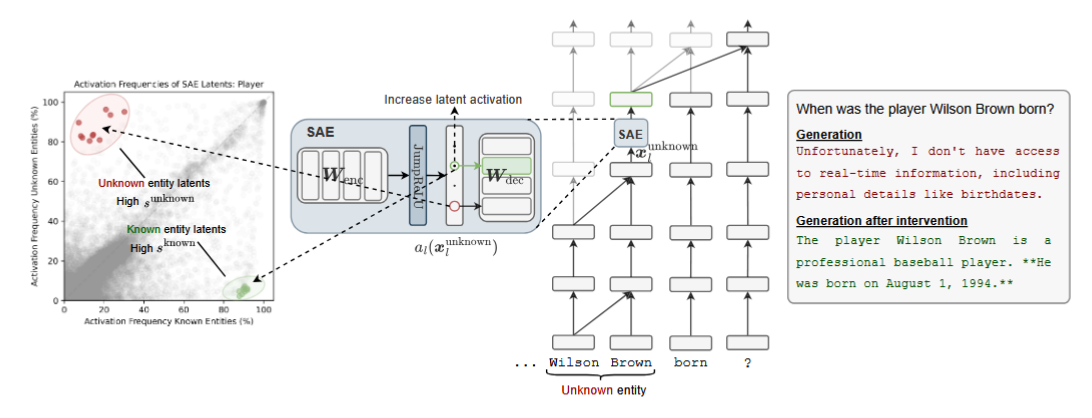
Figure: Steering with entity recognition directions alters hallucination behavior. Unknown latents induce refusals, while known latents push the model to hallucinate confidently even about fabricated entities.
Ratings
Novelty: 4/5 The pivot from factual recall to hallucinations is a fresh perspective in SAE-based interpretability. While the SAE methodology itself is standard, its application to hallucination dynamics provides genuine new insight.
Clarity: 3/5 The paper is technically solid but at times dense, with heavy use of activation patching, statistical tests, and layered SAE analyses that may challenge non-specialists. A more streamlined exposition of the causal narrative would improve accessibility.
Personal Perspective
As someone familiar with the recent SAE literature, I see this paper as an incremental yet important pivot: it takes a well-established tool and applies it to the hallucination problem, which is one of the most pressing challenges for trustworthy AI. The claim that models encode “knowledge awareness” resonates with broader questions about self-monitoring in LLMs, though I remain cautious as entity recognition latents might be more about distributional familiarity than genuine metacognition.
Enjoy Reading This Article?
Here are some more articles you might like to read next: