Literature Review: Fresh in Memory: Training-Order Recency is Linearly Encoded in Language Model Activations
This paper investigates an elegant but profound question: do language models implicitly remember when they learned something? Through sequential fine-tuning of LLaMA-3.2-1B on disjoint entity datasets, the authors find that model activations encode the order in which information was acquired, forming a nearly linear manifold across training stages. Linear probes can reliably decode this “training-order recency” with around 90% accuracy, and the effect generalizes across architectures, fine-tuning methods (full vs. LoRA), and data styles.
Key Insights
-
Linear Encoding of Temporal Recency Activation centroids corresponding to each fine-tuning stage align in a straight line, ordered by training time. This suggests the existence of a “training-time axis” in latent space.
-
Persistence Beyond Reinforcement Even after extensive fine-tuning on mixed and shuffled data (which erases any explicit temporal signal), the encoding persists with only moderate decay. This implies that gradient descent does not erase historical structure unless explicitly penalized.
-
Generalization Across Runs and Architectures The direction encoding training order is stable across independent runs, data variants, and model families (e.g., Qwen2.5). Such consistency implies that the representation of recency may already be present in pretrained checkpoints.
-
Accessibility and Use by the Model When fine-tuned to report an entity’s training stage, models achieve 80% accuracy on unseen examples, demonstrating that this temporal information is not only present but usable by the model itself.
-
Relation to Knowledge Retention and Forgetting Re-exposure of a dataset moves its centroid to the “most recent” end of the axis, suggesting that the representation reflects recency of exposure rather than initial learning time. This aligns with observations from continual learning about memory overwriting and consolidation.
Example
In a core experiment, LLaMA-3.2-1B is sequentially fine-tuned on six disjoint QA datasets about alias-encoded entities (D1–D6). When activations from test prompts are averaged by stage, the six resulting centroids form a perfectly ordered line in latent space. A probe trained to distinguish D1 from D6 generalizes to new entities with over 90% accuracy. Even after 30 epochs of shuffled-data fine-tuning, this linear structure remains partially intact, indicating long-lived memory traces of training history.
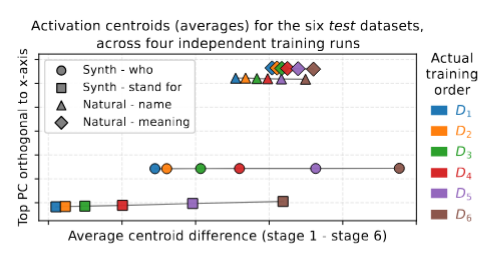
Figure: Activation centroids corresponding to sequential fine-tuning stages align in order of training. Each independent run yields a roughly parallel line, revealing a consistent latent "training-time" direction.
Ratings
Novelty: 4/5 This is a conceptually fresh and surprisingly clean empirical finding, providing the first evidence that training-order information is linearly encoded in LLMs. However, it builds primarily on established probing methods rather than introducing new theoretical machinery.
Clarity: 4/5 The paper is clearly written, with systematic controls and visualization. Some interpretations remain speculative, particularly regarding the origins of the direction and its connection to pretraining, but the exposition is methodical.
Personal Perspective
This study is deceptively simple yet conceptually rich. It hints that neural representations preserve a chronological trace of learning, a form of “implicit timestamping” that parallels biological memory consolidation. The most intriguing extension would be to connect this to catastrophic forgetting, whether the “death” of an old memory corresponds to its fading or collapse along this temporal axis. If so, we might begin to track the lifecycle of specific learned facts in embedding space.
Enjoy Reading This Article?
Here are some more articles you might like to read next: