Literature Review: In-Context Learning and Induction Heads
The post from Anthropic investigates one of the personally most fascinating emergent behaviors in large language models: the ability to learn patterns within the context of a single prompt, without any parameter updates. By dissecting transformer attention mechanisms, the authors identify a concrete circuit, the “induction head”, that enables the model to detect repeated patterns and copy subsequent tokens accordingly. This work provided the first mechanistic grounding for in-context learning, bridging the gap between token-level dynamics and higher-level generalization.
Key Insights
-
Mechanistic Basis of In-Context Learning
The study demonstrates that transformers can learn to perform pattern completion through a circuit-level structure known as an induction head. These heads recognize when a sequence of tokens repeats and then predict the next token based on this pattern, effectively performing “next-token generalization.” -
Phase Transition and the “Aha” Moment
The authors identify a phase-change-like phenomenon during training: initially, models rely on simple bigram statistics, but beyond a certain scale or training step, induction heads suddenly emerge and enable robust in-context learning. -
Copying vs. Conceptual Abstraction
While the analysis focuses on literal token copying, the same mechanism generalizes naturally to higher-level abstraction. Induction heads trained to copy word sequences can, at scale, learn to replicate conceptual patterns, i.e., sequences of reasoning steps, stylistic cues, or discourse structures, providing a scalable substrate for emergent reasoning behaviors observed in LLMs.
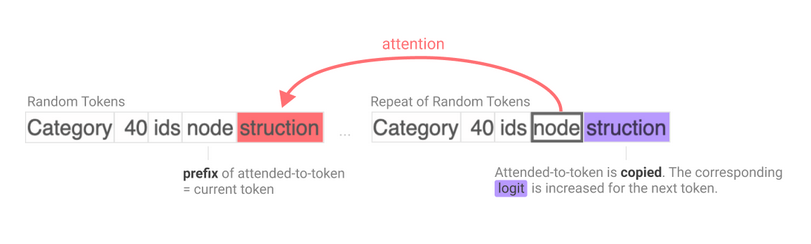
Figure: Visualization of an induction head copying the next token in a repeated pattern. When the model sees "A B A", the induction head learns to predict "B".
Example
Consider the token sequence “A B A”. A transformer equipped with an induction head learns to map the position of the second “A” to the earlier “B”, effectively copying the next token from the previous occurrence. At scale, this same architecture allows models to recognize patterns such as “if x then y; if a then ___” and complete “y” based on structural analogy, the root of in-context generalization.
Ratings
Novelty: 4.5/5
The work offers a genuinely novel mechanistic understanding of an emergent cognitive-like behavior in transformers. While not theoretically formalized, its empirical clarity and interpretive power make it a cornerstone of modern interpretability research.
Clarity: 4/5
The presentation is remarkably clear, particularly for a blog-style exposition. However, due to the limited mathematical formalism, some explanations rely on intuition rather than theoretical precision.
Personal Perspective
This paper seems to be the groundwork of how we now see in-context learning, not as magic, but as the emergent behavior of simple circuits. Going forward, it would be valuable to connect these induction mechanisms to nonlinear conceptual abstraction, such as how LLMs learn compositional or analogical reasoning. While the essay stops short of a full theoretical account, it sets the stage for a rigorous mechanistic theory of learning without gradient updates, a conceptual milestone in our understanding of transformer capabilities.
Enjoy Reading This Article?
Here are some more articles you might like to read next: