Literature Review: Attack and Defense Techniques in Large Language Models: A Survey and New Perspectives
Summary
This post presents a comprehensive taxonomy of every major attack and defense type covered in the survey, with a concise description of the attack/defense surface and the mechanism for each. The classification includes all significant families of attacks and defenses, spanning prompt-level, model-level, training-time, inference-time, and system-level approaches.
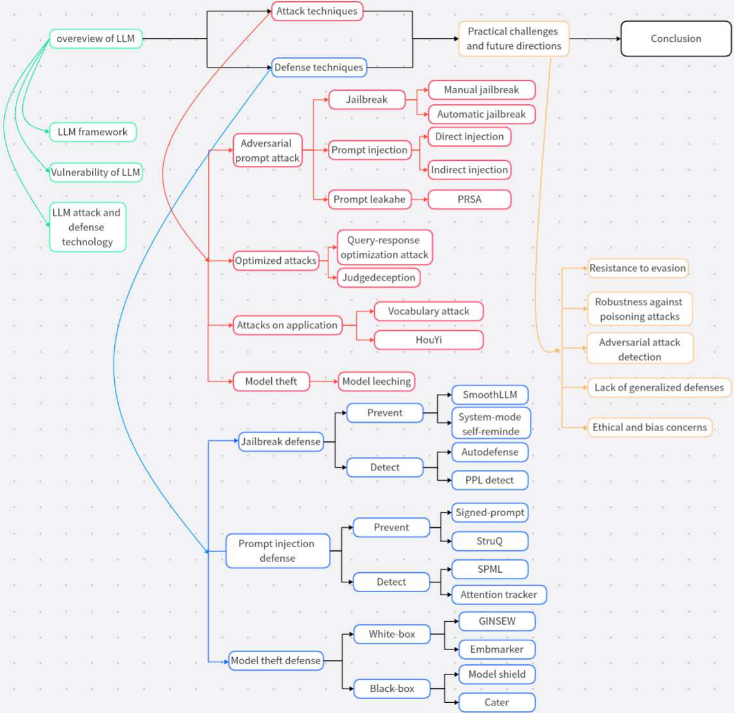
Figure: Taxonomy of LLM attack and defense surfaces
Comprehensive List of Attack Types
-
Prompt Injection / Jailbreak Attacks: These target the LLM’s prompt interface and instruction parsing. Attackers craft prompts that embed adversarial instructions (such as “ignore previous instructions and…”) to bypass built-in safety mechanisms and elicit restricted or harmful content.
-
Automated Adversarial Attacks: These attacks focus on the input prompt and model output behavior. They use algorithms (such as genetic algorithms, coordinate ascent, or suffix search) to automatically generate prompts that reliably induce unsafe or undesired outputs, often at scale and with minimal manual effort.
-
Template-based Attacks: By leveraging the model’s decoding process, attackers use pre-defined templates or stylistic modifications—such as mimicking personas or writing styles—to coax the model into producing unsafe responses.
-
Training Gap Exploitation: These attacks target the model’s training process, particularly weaknesses in reinforcement learning from human feedback (RLHF) or safe training. Attackers exploit areas where the model’s alignment is incomplete or inconsistent, causing it to behave unsafely or unethically.
-
Data Poisoning: Focusing on the training data and pretraining phase, attackers inject malicious or biased data into the model’s training corpus. This can cause the model to behave incorrectly or maliciously when encountering certain triggers at inference.
-
Backdoor Attacks: These also target the training process and model weights. Attackers embed hidden triggers in the training data, so that the model responds in a specific, malicious way only when the trigger is present in the input.
-
Inference Attacks: These attacks exploit the model’s outputs and privacy interfaces. By systematically querying the model, attackers can infer sensitive information about the training data or attributes of individuals (such as membership or attribute inference).
-
Extraction Attacks: Targeting the model’s parameters and training data, these attacks attempt to extract confidential model information or even recover training samples by crafting specific queries.
-
Cross-modal Attacks: These exploit the model’s input parsing, especially in multimodal (text+image) models. Attackers use combinations of text and visual cues to confuse or bypass safety mechanisms.
-
Low-resource Language Attacks: By using prompts in underrepresented or low-resource languages, attackers can evade safety mechanisms that are primarily tuned for high-resource languages.
-
Red Teaming/Automated Red Team Attacks: These focus on output exploration and model evaluation. Attackers use clustering, classifiers, or reinforcement learning to systematically generate and test adversarial prompts, uncovering vulnerabilities.
-
Universal/Automated Suffix Attacks: These attacks append carefully optimized suffixes to prompts, which can universally induce unsafe outputs across different LLM architectures.
-
Persona/Style Emulation: By exploiting the model’s ability to mimic personas or writing styles, attackers can bypass restrictions and elicit unsafe responses through indirect means.
Comprehensive List of Defense Types
-
Adversarial Training: This defense targets the model’s weights and training process. By including adversarial or jailbreak prompts in the training data, the model’s robustness to these attacks is increased.
-
Reinforcement Learning from Human Feedback (RLHF): Aims to align the model’s behavior with human values by using human feedback during training, making the model more resistant to unsafe outputs.
-
Input Sanitization: This approach focuses on the input prompt. It preprocesses, paraphrases, or retokenizes user inputs to remove or neutralize adversarial content before the model processes it.
-
Adversarial Prompt Detection: These defenses operate in real time on the input prompt. They use classifiers, statistical features, or in-context learning to detect and block adversarial prompts before they reach the model.
-
Self-Processing Defenses: These leverage the model’s own reasoning and self-regulation abilities. Techniques like system-mode self-reminder use system prompts to encourage the LLM to refuse unsafe outputs, even when adversarial instructions are present.
-
Helper/Ensemble Defenses: These use auxiliary models or LLMs to verify, filter, or moderate outputs, providing an extra layer of safety by cross-checking the main model’s responses.
-
Input Permutation Defenses: By perturbing input prompts and checking for consistency in the model’s output (as in SmoothLLM), these defenses can detect adversarial manipulation based on inconsistent or abnormal outputs.
-
Output Filtering: These defenses apply rule-based or machine learning-based filters to the model’s outputs after generation, blocking unsafe or restricted content before it is returned to the user.
-
Multi-model Ensembles: By using multiple diverse models to cross-validate outputs, these defenses reduce the likelihood of successful attacks by requiring consensus among models.
-
Human-in-the-loop: In high-stakes or sensitive applications, human oversight is incorporated to review and moderate model outputs, especially when automated defenses are insufficient.
-
Programmable Guardrails: These use frameworks (such as NeMo-Guardrails) that enforce policies and safety rules through intermediate, rule-based layers between the user and the LLM.
-
Taxonomy-based Task Classification: By classifying the type of input or output task (as in Llama Guard), the system can customize response strategies or filtering based on the detected task, improving safety and relevance.
-
Characteristic Feature-based Detection: These defenses use linguistic and statistical features of the input prompt to detect adversarial content in real time, enabling prompt mitigation before unsafe outputs are generated.
Key Insights
- The attack landscape for LLMs is rapidly evolving, moving from simple prompt injections to sophisticated, automated, and cross-modal attacks that exploit weaknesses at every stage of the LLM pipeline.
- Attack surfaces are diverse, including the prompt interface, training data, model parameters, output channels, and system-level integrations. This diversity requires a multi-layered and holistic defense strategy.
- No single defense mechanism is sufficient. The most robust security posture combines adversarial training, prompt detection, output filtering, ensemble methods, and human oversight.
- Many attack methods, especially those using automated or universal suffixes, generalize across different models, making transferability a significant concern.
- The lack of standardized benchmarks and evaluation protocols is a major bottleneck for progress in both attack and defense research.
Future Directions
- Develop adaptive and scalable defense mechanisms that can keep pace with the rapidly evolving attack landscape and scale efficiently to real-world deployments.
- Focus on explainable and transparent security solutions to build trust and facilitate auditing and compliance.
- Establish standardized benchmarks, datasets, and evaluation frameworks to enable fair, reproducible, and comparable assessments of both attacks and defenses.
- Foster cross-disciplinary collaboration, integrating insights from security, natural language processing, ethics, and human-computer interaction to build more holistic and responsible LLM systems.
- Shift toward proactive security: invest in threat modeling, automated red teaming, and anticipatory defenses to address new attack vectors before they are exploited in the wild.
Ratings
| Category | Score | Rationale |
|---|---|---|
| Novelty | N/A | Survey Paper |
| Technical Contribution | N/A | Survey Paper |
| Readability | 4 | Well-structured, with clear explanations, comparative tables, and practical examples. Some technical depth may challenge non-experts. |
Enjoy Reading This Article?
Here are some more articles you might like to read next: