Literature Review: Language Model Circuits Are Sparse In The Neuron Basis
This blog post challenges the prevailing assumption in mechanistic interpretability that the raw neuron basis is fundamentally uninterpretable and requires dictionary learning techniques like Sparse Autoencoders (SAEs) to disentangle features. By utilizing Multilayer Perceptron (MLP) activations rather than outputs and applying an advanced attribution method called RelP, the authors demonstrate that circuits built directly from the neuron basis can be just as sparse and faithful as those constructed using SAEs. This work presents a pipeline for circuit tracing that bypasses the computational overhead and inherent approximation errors of learned feature bases.
Key Insights
1) MLP Activations Provide a Privileged Basis Previous attempts to analyze neuron-level circuits often relied on MLP outputs, which yielded dense and entangled representations. By shifting the analysis to MLP activations before the output projection, the authors isolate a more informative and naturally sparse representation of the model’s internal computation.
2) Improved Attribution Methods Close the Gap Traditional circuit tracing heavily relies on Integrated Gradients, which introduces significant noise and computational inefficiency in deep networks. Substituting this with the RelP attribution method significantly improves the precision of identifying causally relevant neurons, eliminating the performance gap between raw neurons and SAE features.
3) Learned Bases Introduce Unnecessary Artifacts While SAEs and Cross-Layer Transcoders successfully disentangle concepts, they inherently approximate the original model. This approximation introduces hard-to-interpret error terms and causes features to split or merge unpredictably. Extracting circuits directly from the neuron basis avoids these structural distortions and bypasses the need to retrain dictionaries as models evolve.
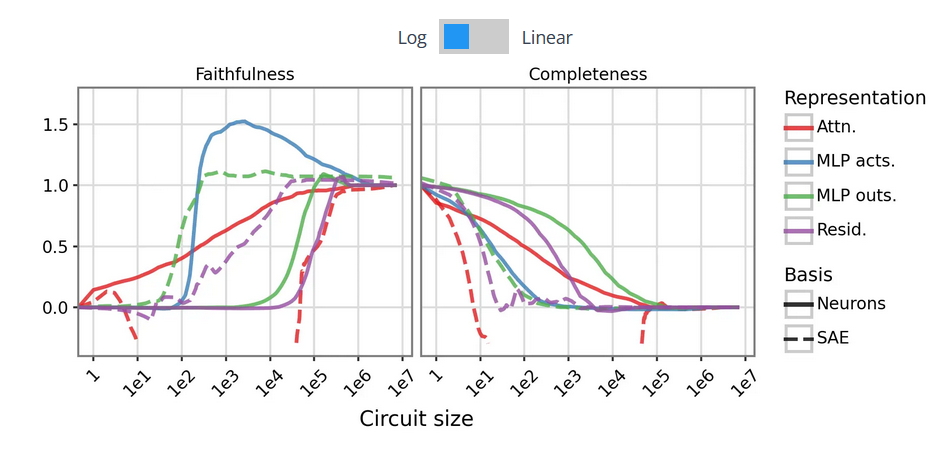
Figure: Comparison of circuit sparsity and faithfulness when tracing causal pathways using raw MLP activations versus traditional Sparse Autoencoder features.
Ratings
Novelty: 4/5 The shift away from the heavily relied upon SAEs back to the raw neuron basis is a somewhat counterintuitive but impactful pivot.
Clarity: 4/5 The methodology is well defined and the comparative ablation studies clearly demonstrate the effectiveness of the two proposed architectural changes. However, the theoretical explanation for why the MLP activations are intrinsically this sparse remains somewhat surface-level (although somewhat inevitable at this point in time).
Personal Perspective
This is a very interesting take on mechanistic interpretability, though I am not entirely sure it solved the fundamental problem I was hoping it would. The process of finding and interpreting a specific circuit from scratch remains highly difficult and noisy. Most of the functions analyzed are established functions we already know exist. However, the conceptual shift away from expensive and unreliable Sparse Autoencoders is highly encouraging. This is a problem I identified in my previous paper, where I attempted to approach SAE interpretability by anchoring it directly on model internals and nodes. This work takes that concept one step further by demonstrating we do not need the SAEs at all, a conclusion I strongly agree with. The user modeling case study is the most interesting addition for me personally. I am very interested to see follow-up work purely focused on this circuit to analyze how Large Language Models encode stereotypes and biases, and how those internal representations dynamically alter their responses based on their model of the user.
Enjoy Reading This Article?
Here are some more articles you might like to read next: