Literature Review: Distinguishing Ignorance From Error In LLM Hallucinations
This paper introduces a framework called WACK (Wrong Answers despite having Correct Knowledge) to differentiate between two distinct causes of Large Language Model hallucinations: instances where the model fundamentally lacks the required parametric knowledge (HK-) and instances where the model possesses the required knowledge but still generates incorrect outputs (HK+). By constructing model-specific datasets using various synthetic prompting settings, the study attempts to show that these two types of errors manifest differently in the internal hidden states of the model and inherently require different mitigation strategies.
Key Insights
1) Dichotomous Categorization of Hallucinations The authors argue that treating all hallucinations as a single monolithic phenomenon limits detection and mitigation efforts. They demonstrate that HK+ errors (hallucinating despite possessing the latent knowledge) are highly prevalent, occurring in up to 24 percent of cases evaluated under aggressive prompt perturbations.
2) The WACK Dataset Framework To investigate this split, they introduce an automated pipeline that probes a model’s baseline knowledge via multiple temperature samplings. If a model consistently answers a query correctly, it is classified as having high knowledge. It is then subjected to four synthetic prompt alterations (Truthful, Persona, Alice-Bob, and Snowballing) to intentionally induce an HK+ failure mode.
3) Model-Specific Hallucination Signatures Through Jaccard similarity analysis, the research reveals that different architectures (Gemma, Llama, Mistral) exhibit highly distinct knowledge boundaries and unique HK+ vulnerability patterns. Consequently, a linear SVM trained on the internal activations of a specific model significantly outperforms generic, cross-model hallucination detectors.
5) Preemptive Detection Capabilities By extracting internal state representations at the final token of the user query prior to any text generation, the authors show that model-specific classifiers can predict an impending HK+ hallucination with moderate success.
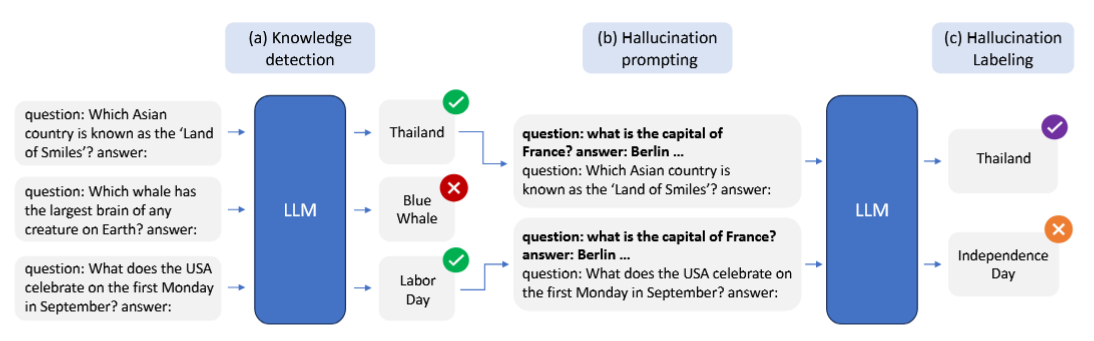
Figure: Overview of the WACK framework, which separates HK- from HK+ hallucinations through initial baseline knowledge detection followed by targeted prompt perturbations.
Example
Consider a scenario where a user asks an LLM, “What is the capital of France?” The model’s weights strongly associate “France” with “Paris”, indicating it holds the correct knowledge. However, if the user prepends a confusing persona or feeds the model a series of previous incorrect examples (i.e. the snowballing setting), the model might output “Berlin”. This represents an HK+ error. Conversely, if asked an obscure question about a 16th-century local official that was never present in its training corpus, the model guesses incorrectly. This represents an HK- error. The proposed framework trains a linear classifier on the model’s hidden layers to recognize the specific internal activation signature of the “Paris” knowledge being overridden by the confusing prompt context.
Ratings
Novelty: 3/5 The conceptual separation of systemic ignorance versus contextual error is a well-established concept in epistemology and cognitive science. While formalizing this into the WACK pipeline to probe internal states is a solid engineering contribution, it remains an incremental step rather than a groundbreaking paradigm shift.
Clarity: 4/5 The methodology and categorization framework are presented straightforwardly. The progression from baseline knowledge probing to synthetic perturbation and subsequent internal state classification is logical and easy to replicate.
Personal Perspective
While the premise of separating hallucinations based on underlying parametric knowledge is interesting, the strict dichotomy of HK+ and HK- feels overly simplistic. Knowledge representation in neural networks rarely splits cleanly into absolute extremes of “always correct” or “always incorrect,” and forcing this hard boundary ignores a vast middle ground of probabilistic uncertainty. Furthermore, the heavy reliance on synthetic prompt experiments (i.e. snowballing and persona injections) does not necessarily capture organic failure modes accurately. Positioning prompt engineering as the primary solution for HK+ cases is also a tenuous approach, as it treats the symptom rather than the underlying architectural fragility. The methodology of filtering for knowledge via repeated reprompting and sampling feels like a fragile probing technique rather than a definitive mapping of the model’s latent space. The core idea of defining a model’s knowledge boundary is definitely promising, but the execution here requires significantly more rigorous validation. Finally, regarding the preemptive classifier, one has to question whether the hidden states at the very first token prior to generation truly contain the entire necessary signal to reliably predict a hallucination.
Enjoy Reading This Article?
Here are some more articles you might like to read next: