Literature Review: No Answer Needed: Predicting LLM Answer Accuracy From Question-Only Linear Probes
This paper investigates whether Large Language Models possess an internal representation of their own ability to answer a question correctly before they begin generating a response. By extracting residual stream activations immediately after the model processes a query but prior to token sampling, the authors train a simple contrastive linear probe to predict accuracy.
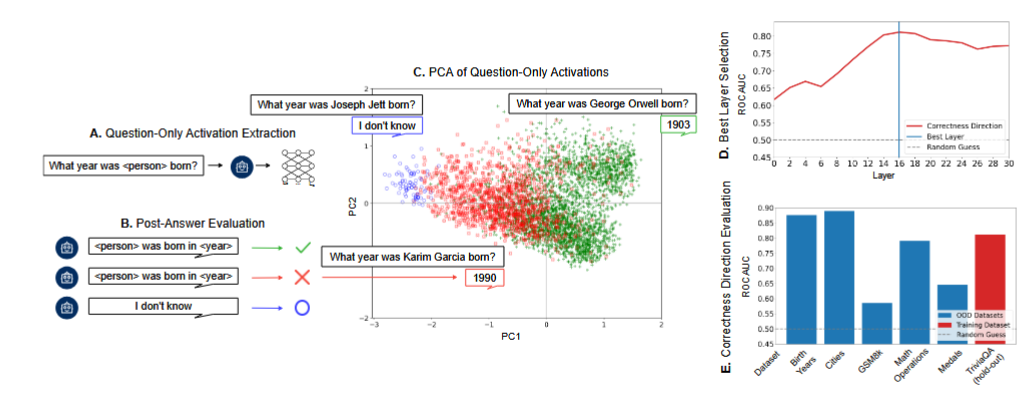
Figure: Proposed methodology for finding the in-advance correctness direction by extracting residual stream activations prior to autoregressive sampling.
Key Insights
-
Linear Separability of Factual Knowledge The internal activations of language models contain a linearly accessible signal that separates questions the model will answer correctly from those it will fail on.
-
Orthogonality of Reasoning and Facts While the correctness direction transfers robustly across trivia and factual datasets, it fails entirely on mathematical reasoning tasks, i.e. GSM8K. This suggests that factual correctness and arithmetic correctness may be structurally distinct or misaligned within the model’s representation space.
-
Latent Confidence and Abstention For models capable of abstaining from a prompt, inputs that result in an “I don’t know” response consistently map to the extreme negative end of the learned correctness direction.This suggests that the identified correctness vector simultaneously serves as a latent confidence axis.
Ratings
Novelty: 3/5 The application of probing to pre-generation correctness is practical and well-executed, but the underlying methodology relies heavily on established linear representation techniques and prior truth-direction literature.
Clarity: 4/5 The authors communicate their experimental setup with commendable clarity and are refreshingly transparent about the boundaries and limitations of their approach, specifically noting the method’s complete failure to generalize to reasoning tasks.
Personal Perspective
This is a simple approach to a problem that I have previously explored in my own research. The methodology is straightforward, and while it lacks the rigorous depth found in more complex interpretability frameworks, the empirical findings are certainly interesting. My primary concern lies in the distinction between causality and correlation regarding these linear directions. It is possible that the simple probe is latching onto correlated dataset features rather than revealing a more causal mechanism of internal self-awareness. Furthermore, while the findings may hold for a tightly scoped research question centered on factual trivia, the generalization to higher-order cognitive tasks is very much up in the air. The authors’ own experiments with the GSM8K dataset demonstrate this failure clearly. While there may be more to be explored here future work should be very careful to isolate pure accuracy from truthfulness and knowledge retrieval (admittedly a highly contested topic of discussion).
Enjoy Reading This Article?
Here are some more articles you might like to read next: